收藏 ≠ 知識
你的瀏覽器書籤列,大概有幾百個連結。我的最愛,Google keep 或隨手丟進 LINE 的訊息,可能更多。但你上一次真的回頭打開其中一篇,是什麼時候?
大部分人的資訊管理流程長這樣:看到好文章 → 存起來 → 感覺自己「處理」了 → 再也沒打開過。這個流程的問題,從來都不是資訊不夠多。問題出在儲存這個動作本身就是終點,後面沒有任何流程接手。
所以 Obsidian 官方出了一個chrome 外掛:Obsidian Web Clipper 。
讓你把「收藏」做得更完善有效。每一次從網頁擷取內容,會直接進入你的 Obsidian 筆記庫,也帶著結構、標籤、上下文。
讓你收進來的瞬間,就已經是一則可以被搜尋、連結、重新使用的筆記。

核心功能:結構化收藏
很多收藏工具都只「存網頁」,但 Obsidian Web Clipper 的差異在於:
它讓你在存的當下就決定這則內容的結構。
他有三個關鍵功能,各自解決一個問題:
指定資料夾 :讓每一則剪藏在進入 Obsidian 的瞬間,就落在你預設的知識結構裡。不管是「待讀」、「AI 工具」、「產品設計」,收進來就歸位。不需要事後一篇一篇拖。
Highlight(重點標記) :整篇文章三千字,真正對你有用的可能就那三段。Highlight 讓你只擷取你畫線的段落,其餘不帶。這一步直接決定了這則筆記未來更高的可用性
屬性設定(Properties) 可以在收藏時自動或手動加上標籤、來源 URL、作者、日期等 metadata。這些屬性讓你的筆記可以被 Dataview 查詢、被篩選、被批次管理。沒有屬性的筆記,就是一座沒有索引的圖書館。
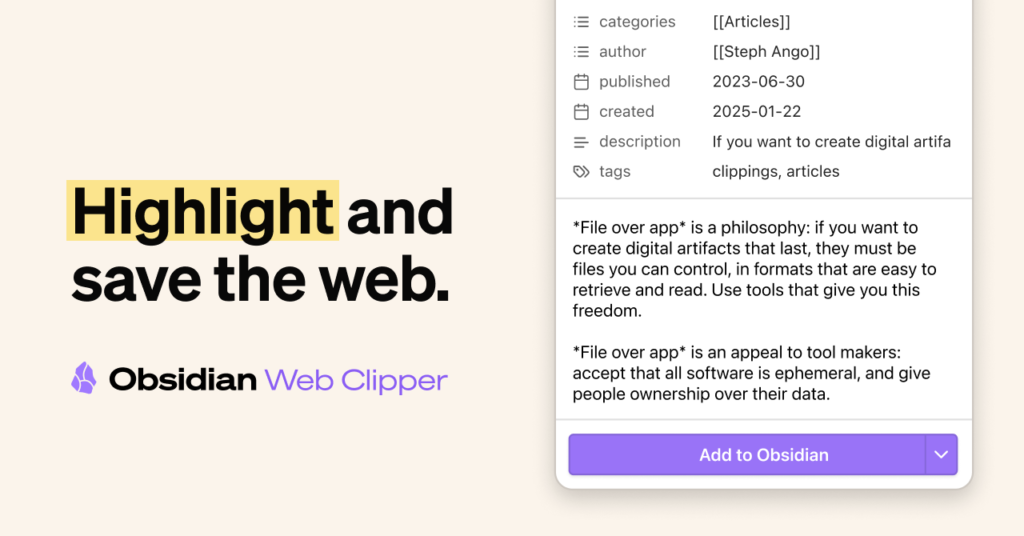
設定與操作:第一次截取前的準備
安裝好 Chrome 擴充功能之後,先進入 Web Clipper 的設定頁面。
第一件事是建立你的截取模板 (Template)
點擊 New template,你會看到幾個關鍵欄位,每一個都決定了截取後的筆記長什麼樣子:
Note name 是筆記的檔名。最簡單的做法是填入 {{title}},它會自動抓取網頁標題當作筆記名稱。大部分情況下這就夠用了,不需要額外設計命名規則。
Note location 是筆記要存進哪個資料夾。這個欄位一定要填。把它指向你 Vault 裡預設的收錄資料夾,比如 Clippings 或 Inbox,確保每一則截取都有地方落腳,不會散落在根目錄。
Content 的部分比較有趣,這裡可以用變數語法設定截取後自動帶入的屬性。舉幾個常用的:
{{url}}:自動帶入原始網址,方便日後回查來源{{date}}:自動填入截取當天的日期,等於幫每則筆記蓋上時間戳{{author}}:抓取文章作者,追蹤特定作者的觀點時很有用
Note content 則是筆記的正文內容。最基本填 {{content}} 就會把整篇文章存進來。如果你只想要 Highlight 的段落,可以改用對應的 Highlight 變數。
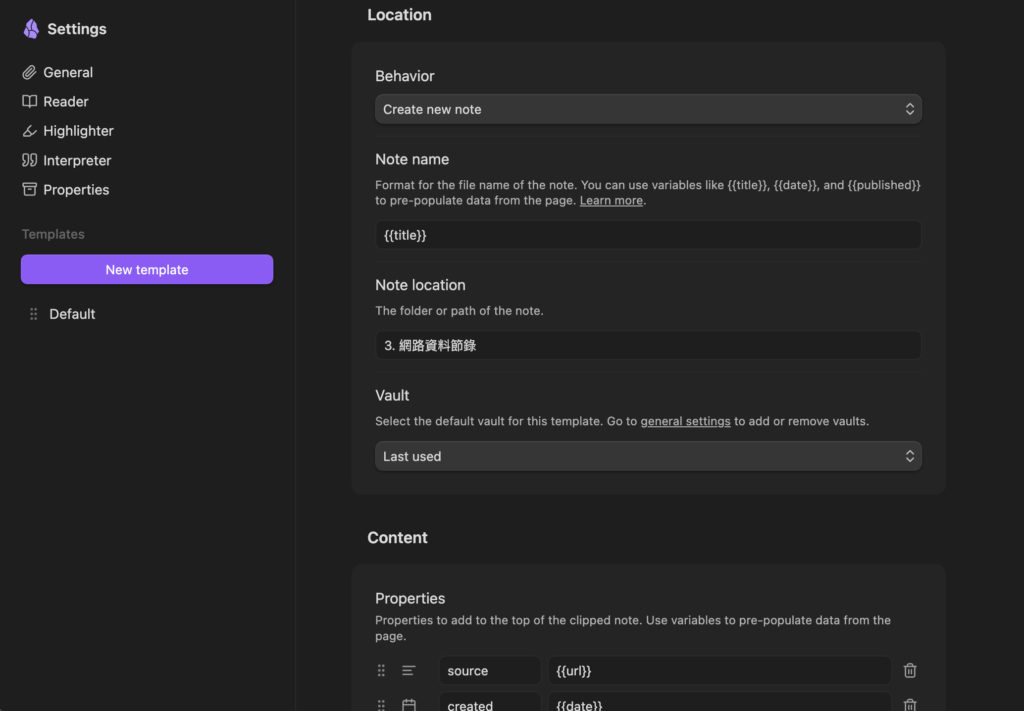
不確定有哪些變數可以用?點開外掛小視窗後,按下左上角的小圓點選單,裡面會列出所有可用的屬性欄位。滑一遍就知道能抓什麼資料。
設定完模板,實際截取就很快了。在任何網頁上點擊 Clipper 圖示,確認資料夾和屬性沒問題,按下儲存,筆記就直接出現在你的 Obsidian Vault 裡。整個動作不超過幾秒鐘。
模板只需要設定一次,之後每次截取都會沿用同樣的規則。摩擦力越低,你越有可能持續做這件事。而持續做,才是知識管理真正有效的唯一條件。
Reader Mode:去除雜訊的閱讀模式
Obsidian Web Clipper 還有內建的 Reader Mode,做的事情很直覺:一鍵把這些干擾全部剝掉,只留下文章標題和正文。
這件事雖然簡單,但對收藏品質的影響很大。沒有 Reader Mode 的時候,你存進 Obsidian 的內容會夾帶一堆導覽列文字、「相關文章」連結、甚至廣告文案。Reader Mode 可以讓你看得更清楚存進去的內容,確保你存進去的,就是你想讀的那篇文章,乾乾淨淨。
更實用的一點是,Reader Mode 也讓 Highlight 變得更精準。在乾淨的閱讀介面上畫重點,你不會不小心選到側邊欄的推薦文字或頁尾的版權聲明。先清理,再擷取,順序對了,後面每一步的品質都會跟著提升。
使用策略:三種收錄方式,決定知識庫的品質
同樣用 Obsidian Web Clipper,三種不同的收錄策略,會養出完全不同品質的知識庫。
整篇收錄(Archive 模式)
把整篇文章原封不動存進來。適合需要保存完整原文的場景,像是重要的產業報告、政策全文、或是你想留底的長篇分析。
重點摘錄(Highlight 模式)
只保留你畫線的段落。一篇三千字的文章,可能濃縮成三百字的重點筆記。
這是我最推薦的方式。原因很簡單:未來的你,只會讀短的東西。三百字的重點筆記,你三十秒就能掃完,馬上想起這篇在講什麼。三千字的全文?你會直接跳過。
重點摘錄的另一個好處是,「選擇要 Highlight 什麼」這個動作本身就是一次思考。你在讀的時候被迫判斷:哪些是核心觀點?哪些只是鋪陳?這個判斷過程,就已經在幫你消化內容了。
結構化收錄(Highlight + 屬性 + 標籤)
在重點摘錄的基礎上,再加上分類標籤、關鍵字、來源資訊。
這一步的價值,要等你的知識庫累積到一定規模才會顯現。當你有五百則筆記的時候,能不能用標籤快速找到「所有關於 RAG 技術的來源文章」,或是用 Dataview 列出「最近三個月收錄的 AI 工具評測」,完全取決於你當初存的時候有沒有把屬性填好。
三種方式沒有絕對的好壞。但核心差異在於:你收進來的東西,六個月後還能不能被你找到、讀懂、用上。

建立你的資訊輸入系統
大部分人經營 Obsidian,花最多心思在「內部怎麼整理」——資料夾結構、INDEX、雙向連結的邏輯。但很少人認真想過「外部資訊怎麼進來」。
這就像蓋了一座分類精美的圖書館,卻沒有設計進書流程。新書來了,隨手往門口一丟。再精美的書架也沒用。
Obsidian Web Clipper 解決的就是這個進書流程。它讓每一則從外部進來的內容,在進門的瞬間就帶著結構、標籤、和脈絡。你的知識庫不需要靠定期大掃除來維持秩序,因為每一則筆記從誕生的那一刻就已經歸位了。
當輸入端的品質穩定了,你的 Obsidian 才會從「一堆筆記的集合」,慢慢長成一個你真的會回頭翻、真的能產出東西的知識系統。